 |
Главная |


Математическое описание процесса обучения
|
из
5.00
|
За редким исключением, для настройки весовых коэффициентов нейронных сетей, предназначенных для классификации, обнаружения или сегментации, используют обучение с учителем, т.е. обучение по набору примеров, содержащих входные данные и целевые выходные данные. Рассмотрим процесс обучения подробнее.
Пусть функция f – это функция нейронной сети, описывающая зависимость выходных значений от входных. По поставленной задаче и классу функций F обучение означает использование множества наблюдений для нахождения функции f* ∈ F, которая решает задачу в некотором оптимальном смысле [46]. Для нахождения оптимального решения необходимо ввести функционал эмпирического риска (эмпирический риск – это средняя величина ошибки алгоритма на обучающей выборке) 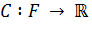 такой, что для оптимального решения функция риска будет минимальна:
такой, что для оптимального решения функция риска будет минимальна:
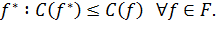
| (11) |
Поскольку решение зависит от данных и должно им соответствовать, функция эмпирического риска (или функция ошибки, функция потерь) зависит от наблюдаемых данных. В случае обучения с учителем это набор входных данных X и ответы, соответствующие им – целевые выходные данные Y. Один из способом настройки нейронной сети на такую задачу – минимизация отклонения предсказанных сетью ответов f(X) на набор входных данных X от целевых выходных данных Y, для чего можно использовать, например, среднеквадратичную функцию эмпирического риска (выражение (12)) (при этом вид функции f зафиксирован).
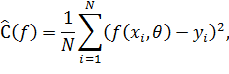
| (12) |
где N – кол-во обучающих примеров;
θ – настраиваемые весовые коэффициенты нейронной сети, по которым ведется оптимизация.
Стандартный алгоритм обучения с учителем нейронной сети, алгоритм обратного распространения ошибки – это итеративный градиентный алгоритм, модификация классического метода градиентного спуска. Суть его заключается в том, что сначала сеть производит вывод предсказания по обучающему примеру (или набору, батчу примеров), затем по функции ошибки рассчитывается величина ошибки на выходе сети, и по полученному значению происходит последовательный расчет частных производных весов и их перенастройка от последнего слоя к начальному. Поэтому функция ошибки должна быть дифференцируема.
Поскольку наборы данных, используемые для обучения глубокой нейронной сети, должны быть большими (для современных сетей классификации и обнаружения требуются десятки и сотни тысяч изображений), практически невозможно уместить их в оперативной памяти целиком. Поэтому глубокие нейронные сети чаще всего обучаются стохастически, т.е. на каждой итерации алгоритма обучения, изменяющей весовые коэффициенты, используется не весь набор данных, а лишь его часть. К тому же, обычно оптимизируемая функция является невыпуклой, и использование различных на каждой итерации небольших групп обучающих примеров снижает вероятность «застревания» модели в локальном минимуме.
Рассмотрим подробнее метод стохастического градиентного спуска и его модификации.
|
из
5.00
|
Обсуждение в статье: Математическое описание процесса обучения |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы