 |
Главная |


Основные числовые характеристики выборки
|
из
5.00
|
| Негруппированная выборка | Группированная выборка |
| 1.Среднее арифметическое выборки | |
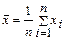
| 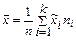
|
| 2.Дисперсия выборки | |
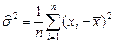
| 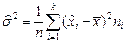
|
3.Исправленная дисперсия выборки: 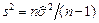
| |
4. Размах выборки: 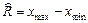
|
Тема 5. Статистические методы оценивания параметров распределений, проверки гипотез и исследования зависимостей.
5.1 Точечные оценки.
Одной из основных задач математической статистики является оценканеизвестных параметров, характеризующих распределение генеральной совокупности 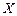 . Совокупность независимых случайных величин
. Совокупность независимых случайных величин 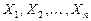 , каждая из которых имеет то же распределение, что и случайная величина называют случайной выборкой объёма
, каждая из которых имеет то же распределение, что и случайная величина называют случайной выборкой объёма 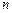 из генеральной совокупности и обозначают
из генеральной совокупности и обозначают 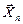 . Любую функцию
. Любую функцию 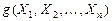 случайной выборки называют статистикой.
случайной выборки называют статистикой.
Если функция распределения 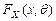 генеральной совокупности известна с точностью до параметра
генеральной совокупности известна с точностью до параметра 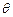 , то его точечной оценкой называют статистику
, то его точечной оценкой называют статистику 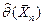 , значение которой
, значение которой 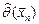 на данной выборке
на данной выборке 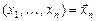 принимают за приближённое значение неизвестного параметра :
принимают за приближённое значение неизвестного параметра : 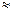 .
.
Чтобы точечные оценки давали «хорошее» приближение оцениваемых параметров, они должны удовлетворять определённым требованиям. «Хорошей» считается оценка, обладающая свойствами состоятельности, несмещённости и эффективности. Оценка называется: 1) состоятельнойоценкой параметра , если при неограниченном увеличении объёма выборки она сходится по вероятности к оцениваемому параметру, т.е. 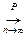 ; 2) несмещённой(оценкой без систематических ошибок), если её математическое ожидание при любом равно оцениваемому параметру, т.е.
; 2) несмещённой(оценкой без систематических ошибок), если её математическое ожидание при любом равно оцениваемому параметру, т.е. 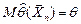 ; 3) эффективной(в некотором классе несмещённых оценок), если она имеет минимальную дисперсию в этом классе.
; 3) эффективной(в некотором классе несмещённых оценок), если она имеет минимальную дисперсию в этом классе.
Пусть распределение генеральной совокупности известно с точностью до вектора параметров 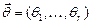 и требуется найти значение его оценки по выборке
и требуется найти значение его оценки по выборке 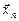 .
.
Оценкой метода моментов вектора параметров 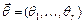 называют статистику
называют статистику 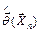 значение
значение 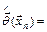
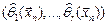 которой для любой выборки удовлетворяет системе уравнений:
которой для любой выборки удовлетворяет системе уравнений:
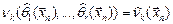 ,
, 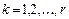 ,
,
где 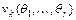 - теоретические начальные моменты
- теоретические начальные моменты 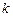 -го порядка случайной величины ,
-го порядка случайной величины , 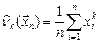 - эмпирические начальные моменты -го порядка выборки . В систему уравнений метода моментов могут входить и уравнения вида
- эмпирические начальные моменты -го порядка выборки . В систему уравнений метода моментов могут входить и уравнения вида  , где
, где  - теоретические центральные моменты -го порядка случайной величины ,
- теоретические центральные моменты -го порядка случайной величины , 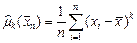 эмпирические центральные моменты -го порядка выборки . Часто для нахождения значения оценки одного параметра используют первый начальный момент. Для нахождения значений оценок двух
эмпирические центральные моменты -го порядка выборки . Часто для нахождения значения оценки одного параметра используют первый начальный момент. Для нахождения значений оценок двух
параметров используют первый начальный и второй центральный моменты.
Оценкой метода максимального правдоподобиявектора параметров называют статистику , значение 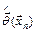 которой для любой выборки удовлетворяет условию:
которой для любой выборки удовлетворяет условию: 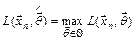 , где
, где 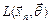 - функция правдоподобия выборки ,
- функция правдоподобия выборки ,  - множество всех возможных значений вектора параметров
- множество всех возможных значений вектора параметров 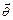 .
.
Функция правдоподобия имеет вид:
1) 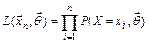 - для дискретной случайной величины
- для дискретной случайной величины 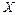 ;
;
2) 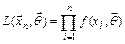 - для непрерывной случайной величины .
- для непрерывной случайной величины .
Если функция 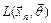 дифференцируема как функция аргумента
дифференцируема как функция аргумента 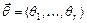 для любой выборки и максимум достигается во внутренней точке
для любой выборки и максимум достигается во внутренней точке 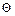 , то значение точечной оценки максимального правдоподобия находят, решая систему уравнений максимального правдоподобия:
, то значение точечной оценки максимального правдоподобия находят, решая систему уравнений максимального правдоподобия: 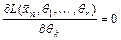 ,
, 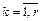 . Нахождение упрощается, если максимизировать не саму функцию правдоподобия, а её логарифм
. Нахождение упрощается, если максимизировать не саму функцию правдоподобия, а её логарифм 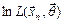 , так как при логарифмировании точки экстремума остаются теми же, а уравнения, как правило, упрощаются и записываются в виде:
, так как при логарифмировании точки экстремума остаются теми же, а уравнения, как правило, упрощаются и записываются в виде: 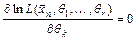 , .
, .
5.2 Интервальные оценки.
Если функция распределения 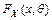 генеральной совокупности известна с точностью до параметра , то его интервальной оценкой или доверительным интерваломназывается случайный интервал
генеральной совокупности известна с точностью до параметра , то его интервальной оценкой или доверительным интерваломназывается случайный интервал 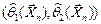 , который накрывает неизвестное значение параметра с заданной вероятностью
, который накрывает неизвестное значение параметра с заданной вероятностью 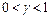 , т.е.
, т.е. 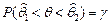 . Число
. Число 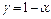 называется доверительной вероятностью, а число
называется доверительной вероятностью, а число 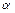 - уровнем значимости. Обычно используются значения
- уровнем значимости. Обычно используются значения 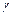 , равные
, равные 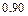 ,
, 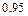 ,
, 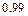 .
.
Точность интервальной оценки характеризуется длиной 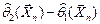 доверительного интервала и зависит от объёма
доверительного интервала и зависит от объёма 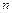 выборки и доверительной вероятности . Очевидно, что, чем меньше длина доверительного интервала, тем точнее оценка. Доверительный интервал, симметричный относительно точечной оценки , определяется формулой
выборки и доверительной вероятности . Очевидно, что, чем меньше длина доверительного интервала, тем точнее оценка. Доверительный интервал, симметричный относительно точечной оценки , определяется формулой 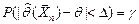 и имеет вид
и имеет вид 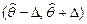 , где
, где 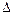 характеризует отклонение выборочного значения параметра от его истинного значения и называется предельной ошибкой выборки. Доверительные интервалы часто строятся в предположении, что выборка получена из генеральной совокупности, имеющей нормальное распределение.
характеризует отклонение выборочного значения параметра от его истинного значения и называется предельной ошибкой выборки. Доверительные интервалы часто строятся в предположении, что выборка получена из генеральной совокупности, имеющей нормальное распределение.
Доверительный интервал для параметра 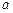 нормально распределённой генеральной совокупности.
нормально распределённой генеральной совокупности.
| Параметр | Точечная оценка | Доверительный интервал |
( 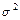 неизвестна) неизвестна)
| 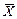
| 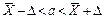 , где , где 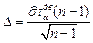 , ,
|
Здесь: 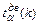 , где
, где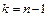 - двусторонняя критическая точка распределения Стьюдента (находится с помощью специальных таблиц).
- двусторонняя критическая точка распределения Стьюдента (находится с помощью специальных таблиц).
5.3. Проверка статистических гипотез.
Статистической гипотезой 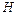 называют любое предположение относительно параметров или вида распределения генеральной совокупности (случайной величины) . Гипотезы относительно неизвестного значения параметра распределения генеральной совокупности (случайной величины) называются параметрическимии непараметрическими в иных случаях. Статистическая гипотеза называется простой, если она однозначно определяет распределение , в противном случае она называется сложной. Проверяемая гипотеза называется основной и обозначается
называют любое предположение относительно параметров или вида распределения генеральной совокупности (случайной величины) . Гипотезы относительно неизвестного значения параметра распределения генеральной совокупности (случайной величины) называются параметрическимии непараметрическими в иных случаях. Статистическая гипотеза называется простой, если она однозначно определяет распределение , в противном случае она называется сложной. Проверяемая гипотеза называется основной и обозначается 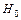 . Наряду с гипотезой рассматривают одну из альтернативных гипотез
. Наряду с гипотезой рассматривают одну из альтернативных гипотез 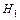 , противоречащих основной. Например, если проверяется гипотеза о равенстве параметра
, противоречащих основной. Например, если проверяется гипотеза о равенстве параметра 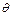 распределения некоторому заданному значению
распределения некоторому заданному значению 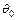 , т.е.
, т.е. 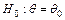 , то в качестве альтернативной гипотезы, как правило, рассматривается одна из следующих гипотез:
, то в качестве альтернативной гипотезы, как правило, рассматривается одна из следующих гипотез: 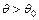 ,
, 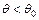 ,
, 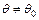 . Выбор альтернативы определяется конкретной постановкой задачи.
. Выбор альтернативы определяется конкретной постановкой задачи.
Правило, по которому принимается решение принять или отклонить основную гипотезу , называется критерием 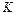 проверки гипотезы. Критерий задают с помощью критического множества
проверки гипотезы. Критерий задают с помощью критического множества 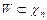 , где
, где 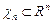 - выборочное пространство (множество всех возможных значений случайной выборки
- выборочное пространство (множество всех возможных значений случайной выборки 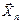 ). Решение принимают на основе выборки
). Решение принимают на основе выборки 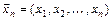 наблюдаемых значений случайной величины , используя для этого подходящую статистику
наблюдаемых значений случайной величины , используя для этого подходящую статистику 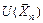 , называемую статистикой критерия . При проверке параметрической гипотезы в качестве статистики критерия выбирают ту же статистику, что и при оценивании параметра .
, называемую статистикой критерия . При проверке параметрической гипотезы в качестве статистики критерия выбирают ту же статистику, что и при оценивании параметра .
Решение принимают следующим образом: 1) если выборка 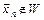 , то принимают основную гипотезу ; 2) если выборка
, то принимают основную гипотезу ; 2) если выборка 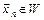 , то основную гипотезу отклоняют и принимают альтернативную гипотезу .
, то основную гипотезу отклоняют и принимают альтернативную гипотезу .
При использовании любого критерия возможны ошибки двух видов:
1) отклонить верную основную гипотезу - ошибка первого рода;
2) принять неверную основную гипотезу - ошибка второго рода.
Вероятности совершения ошибок первого и второго рода обозначают и 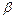 :
: 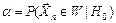 ,
, 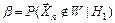 , где
, где 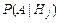 - вероятность события
- вероятность события 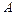 при условии, что справедлива гипотеза
при условии, что справедлива гипотеза 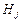 ,
, 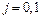 . Вероятность совершения ошибки первого рода называют также уровнем значимости критерия , а величину
. Вероятность совершения ошибки первого рода называют также уровнем значимости критерия , а величину 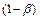 , равную вероятности отклонить основную гипотезу , когда она неверна, называют мощностью критерия. Уровень значимости определяет «размер» критического множества. Обычно используются значения , равные
, равную вероятности отклонить основную гипотезу , когда она неверна, называют мощностью критерия. Уровень значимости определяет «размер» критического множества. Обычно используются значения , равные 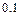 ,
, 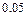 ,
, 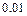 .
.
Проверка статистической гипотезы основывается на принципе, в соответствии с которым маловероятные события считаются невозможными, т.е. если выборка 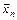 попадает в критическое множество
попадает в критическое множество 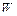 с исключительно малой вероятностью, то естественно предположить, что утверждение, которое привело к этому маловероятному событию, не соответствует истине и отклонить его. Поступая так, мы будем отклонять в действительности верную основную гипотезу крайне редко – не более чем в
с исключительно малой вероятностью, то естественно предположить, что утверждение, которое привело к этому маловероятному событию, не соответствует истине и отклонить его. Поступая так, мы будем отклонять в действительности верную основную гипотезу крайне редко – не более чем в 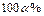 случаев. Поэтому за основную гипотезу естественно принять утверждение, отклонение которого, когда оно в действительности является верным, приводит к более тяжёлым последствиям, чем его принятие при справедливости альтернативы.
случаев. Поэтому за основную гипотезу естественно принять утверждение, отклонение которого, когда оно в действительности является верным, приводит к более тяжёлым последствиям, чем его принятие при справедливости альтернативы.
Общая схема проверки параметрической гипотезы состоит в следующем: 1) формулируется альтернативная гипотеза ; 2) задаётся уровень значимости ; 3) выбирается статистика критерия проверки гипотезы ; 4) определяется выборочное распределение статистики при условии, что гипотеза является верной; 5) по заданным значениям и определяется критическое множество критерия в зависимости от формулировки альтернативной гипотезы ; 6) по выборке вычисляется наблюдаемое значение 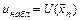 статистики критерия; 7) принимается статистическое решение: если
статистики критерия; 7) принимается статистическое решение: если 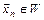 , то основная гипотеза отклоняется как не согласующаяся с данными выборки; если
, то основная гипотеза отклоняется как не согласующаяся с данными выборки; если 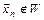 , то принимается, т.е. считается, что гипотеза не противоречит данным выборки.
, то принимается, т.е. считается, что гипотеза не противоречит данным выборки.
Критерии, используемые для проверки гипотезы 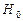 о виде распределения случайной величины (генеральной совокупности) называют критериями согласия (с основной гипотезой), при этом альтернатива
о виде распределения случайной величины (генеральной совокупности) называют критериями согласия (с основной гипотезой), при этом альтернатива 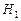 , как правило, не формулируется, подразумевая под ней «всё остальное». Одним из наиболее широко применяемых на практике критериев согласия, является критерий согласия
, как правило, не формулируется, подразумевая под ней «всё остальное». Одним из наиболее широко применяемых на практике критериев согласия, является критерий согласия 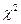 («хи-квадрат»).
(«хи-квадрат»).
Критерий «хи-квадрат» в качестве меры расхождения эмпирического и теоретического законов распределения случайной величины использует значения статистики 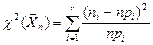 , где - объём выборки;
, где - объём выборки; 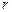 -число непересекающихся множеств
-число непересекающихся множеств 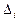 на которые разбита область возможных значений случайной величины ;
на которые разбита область возможных значений случайной величины ; 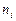 -эмпирическая частота попадания в ;
-эмпирическая частота попадания в ; 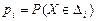 -вероятность попадания в , вычисленная для теоретического закона распределения . Закон распределения статистики
-вероятность попадания в , вычисленная для теоретического закона распределения . Закон распределения статистики 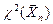 при
при 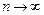 независимо от вида закона распределения случайной величины стремится к закону -распределения с
независимо от вида закона распределения случайной величины стремится к закону -распределения с 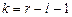 степенями свободы (
степенями свободы ( 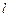 -число параметров теоретического закона распределения
-число параметров теоретического закона распределения 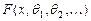 , вычисляемых по выборке). Для его применения практически достаточно, чтобы
, вычисляемых по выборке). Для его применения практически достаточно, чтобы 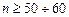 .
.
Общая схема проверкинепараметрическойгипотезы , утверждающей, что случайная величина имеет теоретический закон распределения , состоит в следующем.
1) Задают уровень значимости .
2) По выборке находят значения оценок 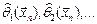 неизвестных параметров предполагаемого закона распределения .
неизвестных параметров предполагаемого закона распределения .
3) Множество возможных значений случайной величины разбивают на непересекающихся множеств 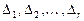 : интервалов, если - непрерывная величина или групп отдельных значений, если - дискретная величина, и подсчитывают их частоты ,
: интервалов, если - непрерывная величина или групп отдельных значений, если - дискретная величина, и подсчитывают их частоты , 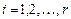 .
.
4) Используя предполагаемый закон распределения вычисляют вероятности , - вероятности того, что наблюдаемое значение принадлежит множеству . Замечание. Критерий «хи-квадрат» использует тот факт, что случайные величины 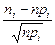 , , имеют распределения, близкие к нормальному
, , имеют распределения, близкие к нормальному 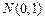 . Чтобы это утверждение было достаточно точным, необходимо, чтобы для всех выполнялось условие
. Чтобы это утверждение было достаточно точным, необходимо, чтобы для всех выполнялось условие 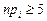 . Если для некоторых это условие не выполняется, то их объединяют с соседними.
. Если для некоторых это условие не выполняется, то их объединяют с соседними.
5) По заданным значениям и определяют критическое множество критерия «хи-квадрат»: 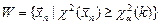 , , где
, , где 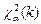 - критическая точка
- критическая точка 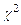 -распределения (находится с помощью специальных таблиц). Замечание. Если проводилось объединение , то - число множеств , оставшихся после их объединения.
-распределения (находится с помощью специальных таблиц). Замечание. Если проводилось объединение , то - число множеств , оставшихся после их объединения.
6) По выборке вычисляют наблюдаемое значение 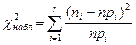 статистики критерия «хи-квадрат».
статистики критерия «хи-квадрат».
7) Принимают решение: если , то основная гипотеза отклоняется как не согласующаяся с данными выборки; если , то принимается, т.е. считается, что гипотеза не противоречит данным выборки.
5.4 Корреляционно-регрессионный анализ.
На практике часто бывает важно знать, существует ли зависимость между некоторыми наблюдаемыми величинами, насколько тесно они связаны между собой, можно ли по значению одной величины сделать какие-либо выводы о предполагаемом значении другой величины и т.д. Для решения задач такого рода и применяется корреляционно-регрессионный анализ.
Пусть 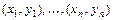 - выборка из двумерной генеральной совокупности
- выборка из двумерной генеральной совокупности 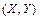 . Предварительное представление о зависимости между случайными величинами и
. Предварительное представление о зависимости между случайными величинами и 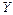 можно получить, изобразив в прямоугольной системе координат на плоскости точки
можно получить, изобразив в прямоугольной системе координат на плоскости точки 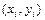 . Такое графическое представление двумерной выборки называют диаграммой рассеивания (корреляционным полем). Количественной характеристикой степени линейной зависимости между величинами и является коэффициент корреляции
. Такое графическое представление двумерной выборки называют диаграммой рассеивания (корреляционным полем). Количественной характеристикой степени линейной зависимости между величинами и является коэффициент корреляции 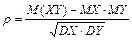 . Его состоятельной оценкой служит статистика
. Его состоятельной оценкой служит статистика 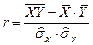 , где
, где 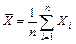 ,
, 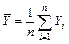 ,
, 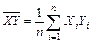 ,
, 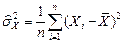 ,
, 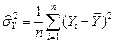 .
.
Если 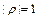 , то все выборочные точки ,
, то все выборочные точки , 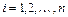 лежат на одной прямой. При
лежат на одной прямой. При 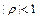 выборочные данные только имеют тенденцию сосредотачиваться около прямых:
выборочные данные только имеют тенденцию сосредотачиваться около прямых: 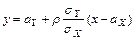 ,
, 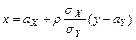 , называемых (теоретическими) прямыми регрессии на и на , соответственно. Здесь
, называемых (теоретическими) прямыми регрессии на и на , соответственно. Здесь 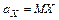 ,
, 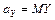 . Первое уравнение даёт наилучший в среднем квадратичном прогноз ожидаемых значений по наблюдениям , второе – прогноз значений по наблюдениям .
. Первое уравнение даёт наилучший в среднем квадратичном прогноз ожидаемых значений по наблюдениям , второе – прогноз значений по наблюдениям .
Прямые 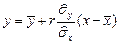 ,
, 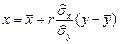 называются эмпирическими прямыми регрессии на и на , соответственно. Здесь
называются эмпирическими прямыми регрессии на и на , соответственно. Здесь 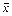 ,
, 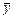 ,
, 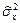 ,
, 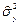 ,
, 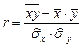 - найденные по выборке ,
- найденные по выборке , 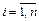 , значения статистик
, значения статистик 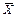 ,
, 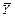 ,
, 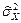 ,
, 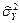 ,
, 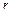 , являющихся состоятельными оценками параметров
, являющихся состоятельными оценками параметров 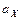 ,
, 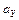 ,
, 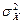 ,
, 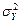 ,
, 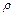 двумерной генеральной совокупности.
двумерной генеральной совокупности.
Проверка гипотезы о значимости выборочного коэффициента корреляции .
Гипотеза 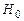
| Статистика критерия | Критическое множество |
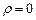
| 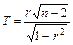
| 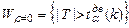 ,где ,где 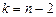
|
Здесь: 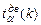 - двусторонняя критическая точка распределения Стьюдента (находится с помощью специальных таблиц), .- объём выборки.
- двусторонняя критическая точка распределения Стьюдента (находится с помощью специальных таблиц), .- объём выборки.
|
из
5.00
|
Обсуждение в статье: Основные числовые характеристики выборки |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы